索引在存储引擎层实现,所以我们先介绍一下不同的数据库引擎。
一.数据库引擎的类型
1. InnoDB
MySQL的默认事务型引擎,使用mvcc来支持高并发,实现了四个标准的隔离级别,默认级别是rr,通过间隙锁策略防止幻读。
InnoDB表基于聚簇索引建立的,数据存储在表空间中,可以将每个表的数据和索引存放在单独的文件中,支持热备份,其他的引擎都不支持。他的索引结构和其他存储引擎有很大不同,他的二级索引中必须包含主键
2. MyISAM
Mysql5.1及之前版本的默认引擎,有大量特性,包括全文索引、压缩、空间函数,不支持事务和行级锁,崩溃后无法安全恢复。
MyISAM会将表存储在两个文件中:数据文件和索引文件。
InnoDB和MyISAM的区别
- InnoDB支持事务,MyISAM不支持
- InnoDB是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而MyISAM是非聚集索引,数据文件是分离的,索引保存的是数据文件的物理地址。主键索引和辅助索引是独立的。
3.Memory
如果需要快速的访问数据,并且这些数据不会被修改,重启后丢失也没有关系,那么使用Memory表很有用,他比MyISAM快一个数量级,因为索欧数据都保存在内存中。重启后结构保留,数据丢失。
二.索引的类型
1.B-Tree索引
实际上在很多引擎中使用的是B+树进行优化比如innoDB,之后再写一篇详细介绍B-树索引的文章,这里先简单介绍一下,他的工作原理,存储引擎不需要进行权标扫描来获取数据,而是从根节点开始搜索,根节点存了指向子节点的指针,根据这些指针向下层搜索,通过比较节点页的值和要查找的值,可以找到合适的指针进入下一层。
索引对多个值进行排序依据的是CREATE TABLE语句中定义索引时列的顺序
可以使用B-Tree索引的查询类型
适用于全键值、键值范围、或者键前缀查找,假设索引建立在姓、名、出生日期上,实际使用如下所示
- 全值匹配: 匹配Cuba Allen、生日是1970-01-01的人
- 匹配最左前缀:可以用于查找姓为Allen的人,即只用第一列
- 匹配列前缀:匹配姓开头为J的
- 匹配范围值:查找姓在Allen和Jack之间的人
- 精确匹配某一列并范围匹配另一列:查找姓为Allen名字是K开头的
优点
- 若果不按引的最左列开始查找,则无法使用:比如无法找到特定生日的人活着名字叫Bill的人,要从索引的最左列开始,所以也无法找找姓氏以某个字母结尾的人
- 不能跳过索引:即使无法找到姓为Smith并且在某个特定日期出生的人
- 如果查询中有某个范围查询,那么他右边的所有列都无法使用索引优化查找:例如where last_name = “Smith” and first_name like “J%” and dob = ‘1990-01-01’,由于第二列是范围查询,所以第三列作废
Tips
- 对于BLOB、TEXT或者很长的VARCHAR类型的列,必须使用前缀索引,因为MySQL不允许索引这些列的完整长度。
- 选择合适的索引列顺序
2.哈希索引
只有精确匹配索引所有列的查询才有效,对于每一行数据,都会对所有的索引列计算一个hashcode,哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针
Innodb有一个功能叫做自适应哈希索引,当innodb注意到某些索引值使用的很频繁的时候,会在内存中基于B-Tree索引之上再创建一个哈希索引。
缺陷
- 索引只包含哈希值和行指针不存储字段值,无法通过索引值来避免读行
- 不是按索引值的顺序存储的,无法排序
- 不支持部分索引列匹配查找
- 只支持等值比较
- 访问哈希索引的数据很快,除非有很多冲突,冲突多的时候维护代价很大
3.空间数据索引(R_Tree)
4. 全文索引
InnoDB和MyISAM中B-Tree实现区别
聚簇索引和非聚簇索引
聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的索引顺序与数据物理排列顺序无关其实就是一个存储的是具体数据,一个存储了物理地址。正是聚簇索引的顺序就是数据的物理存储顺序,所以一个表最多只能有一个聚簇索引,因为物理存储只能有一个顺序。
InnoDB和MyISAM的数据分布对比
下面分别是聚簇索引和非聚簇索引的存储结构图
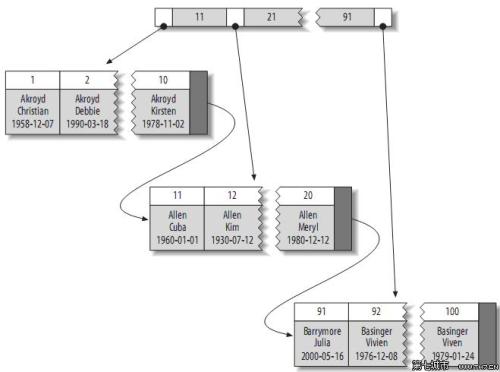



总结:
- InnoDB是聚簇索引,通过主键引用被索引的值,数据文件和索引文件在一起,MyISAM是非聚簇索引,通过物理地址索引被索引的值,数据文件和索引文件在两个文件中
- InnoDB的二级索引需要包含主键,MyISAM不需要,仍然只需要存储地址,他的主键索引有唯一性要求,二级索引没有
- InnoDB索引保存了原格式文件,MyISAM使用了前缀压缩
后记
对于聚簇索引和非聚簇索引的区别,应该从他们存储的区别以及相对应的主键索引和二级索引来说。用查字典来举例的话,聚簇索引类似用拼音检索,物理顺序和逻辑顺序一致,非聚簇索引类似于偏旁部首查找,通过偏旁部首找到页码,也就是相应的物理地址指针。正由于一个字典只有一个排列顺序,所以一个表只有一个聚簇索引。对于聚簇索引对应的主索引和二级索引,他的二级索引包含主键列,在查询的时候需要查询2次,先要查询到主键列,再根据这个值去聚簇索引中查找。对于非聚簇索引的主键索引和二级索引相差不大,存储的都是相应的物理地址。